1.1 序列化定义与作用
想象一下你要把一台组装好的乐高模型寄给远方的朋友。直接邮寄整个模型显然不现实,最好的办法是把它拆解成零件,整齐打包后寄出,朋友收到后再按照说明书重新组装。这个过程就类似于程序中的序列化与反序列化。
序列化本质上是一种对象持久化技术。它把内存中的Java对象转换成字节序列,这个过程就像把三维物体压扁成二维设计图。这些字节序列可以保存到文件、通过网络传输,或者存入数据库。反序列化则是相反的过程,把字节序列恢复成原来的Java对象。
记得我第一次接触序列化是在开发一个游戏存档功能时。玩家辛苦打到的装备和等级数据需要保存到本地文件,下次启动游戏时能够完整还原。如果没有序列化,我们可能需要手动把每个属性值写成文本格式,既繁琐又容易出错。
序列化的核心价值在于它实现了对象状态的保存与重建。无论是分布式系统中的远程调用,还是缓存数据的持久化存储,都离不开这个基础能力。
1.2 Java序列化机制原理
Java的序列化机制设计得相当巧妙。当你让一个对象实现Serializable接口时,就好像给这个对象贴上了“可打包”的标签。这个接口是个标记接口,里面没有任何方法需要实现,它的存在只是为了告诉JVM:“我这个对象允许被序列化”。
序列化的具体过程涉及到底层的ObjectOutputStream。它会遍历对象的所有字段,包括私有字段,然后把它们转换成字节流。这里有个有趣的现象:静态字段不会被序列化,因为它们属于类而不是对象实例。transient关键字修饰的字段也会被跳过,这个设计给了我们控制序列化内容的灵活性。
对象的序列化过程其实是个递归操作。假设你序列化一个Person对象,它包含一个Address类型的字段,那么Address对象也会被自动序列化。整个对象图都会被完整地保存下来。
我遇到过这样的情况:某个类在序列化后修改了结构,导致反序列化失败。这是因为Java序列化机制依赖serialVersionUID来验证版本一致性。如果没有显式声明这个字段,JVM会自动生成一个,类结构的任何改动都会导致这个值变化。

1.3 序列化应用场景
序列化的应用几乎无处不在。在Web开发中,Session的集群共享就是个典型例子。当你的应用部署在多台服务器时,用户的Session对象需要序列化后存储到Redis这样的共享缓存中。
远程方法调用(RMI)是另一个重要场景。客户端调用远程服务器的方法时,参数对象需要序列化后通过网络传输,服务器处理完后再把结果对象序列化传回。虽然现在很多系统改用JSON或Protocol Buffers,但原理是相通的。
深度拷贝也可以借助序列化实现。先把对象序列化成字节流,再立即反序列化,这样就得到了一个完全独立的新对象。这种方法比手动复制每个字段要方便得多,特别是在对象结构复杂的情况下。
缓存系统经常使用序列化。比如把查询结果序列化后存入Redis,下次请求时直接反序列化使用,避免重复的数据库查询。这种用法在电商网站的商品展示、社交媒体的动态流中都很常见。
序列化就像程序的“时间胶囊”,让对象的状态能够穿越时间和空间的限制。理解它的基本原理,能帮助我们在合适的场景做出更好的技术选择。
2.1 序列化性能优化技巧
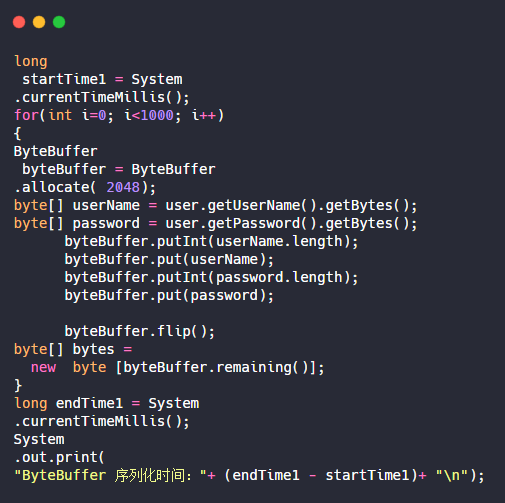
序列化的性能问题往往在数据量增大时才暴露出来。我维护过一个用户行为分析系统,每天要序列化数百万条记录,最初版本的处理时间长得让人难以接受。
减少序列化数据量是最直接的优化方向。使用transient关键字排除不需要持久化的字段,比如计算得出的临时值或可以从其他数据推导出的冗余信息。对象中的缓存字段、会话状态这些运行时特有的数据,通常都不该进入序列化流程。
自定义序列化方法能带来显著提升。通过实现writeObject和readObject方法,你可以精确控制哪些字段被序列化,以及如何序列化。曾经有个案例,某个类包含大量默认值的字段,通过自定义序列化跳过了这些字段,序列化数据大小减少了40%左右。
序列化版本号serialVersionUID应该显式声明。让JVM自动生成这个值会导致版本兼容性问题,还可能因为不同JVM实现产生不一致的结果。显式声明能确保序列化一致性,也便于后续的类演化。
对象重用是另一个技巧。对于频繁序列化的场景,可以考虑复用ObjectOutputStream实例。创建这些流对象的开销不小,特别是在循环中重复创建时。不过要注意线程安全问题,或者为每个线程维护独立的流实例。
2.2 常见错误及解决方案
序列化看似简单,陷阱却不少。最经典的问题莫过于“序列化版本不匹配”。当序列化和反序列化两端的类定义发生变化,又没有妥善处理版本兼容时,各种异常就会接踵而至。
循环引用是个隐蔽的陷阱。如果对象A引用B,B又引用A,标准序列化机制会陷入无限递归。解决方法是实现Externalizable接口,或者使用第三方序列化框架。在某些情况下,重写writeObject方法,手动控制引用关系也是可行的。
安全风险容易被忽视。反序列化过程本质上是在重建对象,如果数据源不可信,攻击者可能构造恶意字节流执行任意代码。生产环境中,对反序列化的数据源一定要做严格校验,或者考虑使用白名单机制。
内存泄漏问题也时有发生。反序列化过程中,如果对象图中包含大量数据,而引用管理不当,就容易导致内存压力。特别是在Android开发中,序列化大对象时更需要谨慎。
我记得有个项目,反序列化时总是出现莫名的ClassCastException。排查后发现是不同类加载器加载了同名类,导致类型系统混乱。这种类加载器相关的问题在容器化环境中尤其常见。
2.3 最佳实践建议
序列化的使用需要平衡便利性和控制力。对于内部系统,Java原生序列化可能足够好用。但在跨语言、需要版本兼容的场景下,JSON、Protocol Buffers或Avro往往是更好的选择。
设计可序列化类时,要考虑到未来的演化需求。字段的增加、删除、类型修改都可能破坏兼容性。提供适当的默认值、使用灵活的集合类型,都能增强系统的鲁棒性。
测试环节不能忽视。应该专门为序列化功能编写测试用例,覆盖正常流程、异常情况、版本升级、数据迁移等各种场景。自动化测试能及早发现问题,避免线上事故。
文档和规范很重要。团队应该明确序列化的使用边界,哪些数据适合序列化,哪些不适合。制定统一的serialVersionUID管理策略,避免各个项目各自为政。
性能监控必不可少。在大流量系统中,序列化的CPU和内存消耗可能成为瓶颈。通过监控关键指标,能够及时发现性能退化,在问题影响用户体验前进行优化。
说到底,序列化是工具而非目的。理解业务需求,选择合适的技术方案,比盲目追求某种“最佳实践”更重要。每个系统都有其独特之处,适合的才是最好的。