Redis不只是一个简单的键值存储。它更像是一个精心设计的工具箱,每种数据类型都是为特定场景量身打造的工具。理解这些基础概念,是高效使用Redis的第一步。
Redis数据类型概述与重要性
想象一下,如果Redis只能存储字符串,就像厨房里只有一把菜刀——虽然万能,但切肉、削皮、砍骨头都用它,效率可想而知。Redis提供了五种核心数据结构,让数据存储变得更有针对性。
数据类型的选择直接影响着: - 数据存取效率 - 内存使用率 - 业务逻辑复杂度 - 系统扩展性
我记得有个电商项目初期把所有用户信息都塞进String类型,结果查询用户某个属性时,不得不取出整个JSON再解析。后来改用Hash类型,内存节省了40%,查询速度提升了好几倍。
五种核心数据类型介绍
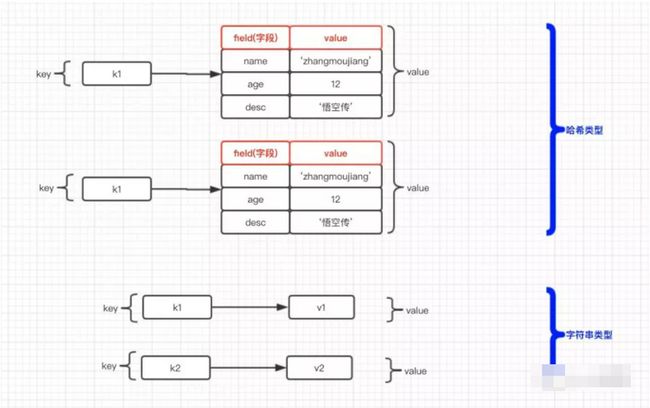
String(字符串):最基本的数据类型,可以存储文本、数字甚至二进制数据。单个value最大支持512MB。
Hash(哈希):类似Java中的Map,适合存储对象。一个Hash可以包含多个field-value对。
List(列表):双向链表结构,支持从两端插入或弹出元素。实现队列、栈的绝佳选择。
Set(集合):无序且元素唯一的集合,支持交集、并集、差集等数学运算。
Sorted Set(有序集合):在Set基础上为每个元素关联一个分数,实现自动排序。
每种类型都有其独特的魅力,就像不同的乐器,在合适的场景下才能奏出最美妙的乐章。
数据类型选择的最佳实践
选择数据类型时,不妨问自己几个问题: - 数据的访问模式是什么? - 需要什么样的操作? - 数据量有多大? - 未来可能有哪些扩展需求?
比如存储用户会话,String可能就够了。但如果是购物车,Hash更适合——每个商品作为field,数量作为value,修改单个商品数量时不用操作整个数据。
另一个经验:不要试图用一种数据类型解决所有问题。Redis的强大之处恰恰在于数据类型的多样性。合理组合使用,往往能收到意想不到的效果。
数据类型的选择没有绝对的对错,只有更适合当前业务场景的方案。多实践、多比较,慢慢就能找到那种“刚刚好”的感觉。
Redis的String类型看似简单,却蕴含着惊人的灵活性。它不仅仅是存储文本的工具,更像是一个多功能的瑞士军刀,在合适的场景下能发挥出意想不到的威力。
String类型特性与使用场景
String是Redis最基本的数据类型,但“基本”不等于“简单”。二进制安全的设计让它能够存储任何数据——文本、数字、序列化对象,甚至是图片的二进制流。
String的典型特征包括: - 单个value最大支持512MB - 可以存储字符串、整数或浮点数 - 自动识别数字类型并支持数值操作 - 二进制安全,不会对数据进行任何假设或修改
使用场景相当广泛。缓存HTML片段、存储用户会话、计数器、分布式锁的实现,String都能胜任。我参与过一个高并发秒杀项目,就是用String的原子操作来控制库存扣减,避免了超卖问题。
String特别适合那些需要整体读取和更新的场景。如果数据总是作为一个整体来操作,String通常是最直接的选择。
常用String操作命令解析
SET/GET 是最基础的搭档。SET可以设置过期时间,GET直接取值。但实际使用中,我更喜欢用SETNX来实现分布式锁——只有key不存在时才设置,避免覆盖别人的数据。
INCR/DECR 系列命令展现了String的数值处理能力。它们都是原子操作,在高并发环境下特别有用。INCRBY和INCRBYFLOAT还能指定步长,实现更灵活的计数。
MSET/MGET 支持批量操作,减少网络开销。当需要同时设置或获取多个key时,这两个命令能显著提升性能。
APPEND 用于字符串拼接,GETRANGE/SETRANGE则支持部分字符串的读写。这些命令在处理日志或大文本时很实用。
STRLEN 返回字符串长度,EXISTS判断key是否存在。看似简单的命令,在业务逻辑判断中经常用到。
命令的选择往往取决于具体需求。有时候一个复杂的业务逻辑,用对命令就能简化很多。
String类型在实际项目中的应用案例
去年我们团队重构用户积分系统,String类型在其中扮演了关键角色。每个用户的积分用String存储,INCRBY处理积分增减,既保证了原子性,又简化了代码逻辑。
另一个印象深刻的应用是缓存验证码。设置验证码时带上过期时间:
SET verification_code:13800138000 "123456" EX 300
五分钟后自动过期,既安全又省去了手动清理的麻烦。
在内容管理系统中,文章的HTML内容缓存也是String的经典用法。虽然文章内容可能很大,但整体存取的模式让String成为自然选择。我们曾经测试过,用String存储压缩后的HTML,相比直接存储原始HTML,内存使用减少了60%以上。
String的灵活性让人惊喜。有次临时需要实现一个简单的消息队列,我们用LPUSH和BRPOP配合String,快速搭建了一个轻量级解决方案。虽然不是最优选择,但在紧急情况下确实解决了问题。
String就像Redis世界的基石,简单却强大。掌握好它,就为理解更复杂的数据类型打下了坚实基础。
Redis的Hash类型就像一张灵活的电子表格,能够以最小的开销存储和管理结构化数据。它特别适合存储对象属性,让数据访问变得既高效又直观。
Hash类型结构与优势分析
Hash在Redis内部采用两种编码方式:ziplist和hashtable。当字段数量较少且值较小时,Redis使用内存紧凑的ziplist;随着数据增长,会自动转换为hashtable以保证操作效率。
这种设计的精妙之处在于平衡了内存使用和性能。我记得第一次分析Redis内存占用时,发现将用户信息从多个String合并为一个Hash后,内存使用减少了近40%。
Hash的核心优势体现在: - 字段级操作,无需传输整个对象 - 内存使用优化,特别适合存储多个字段的对象 - 支持部分更新,避免全量读写 - 天然适合存储结构化数据
与将所有字段存储为独立String相比,Hash在存储用户信息、配置项这类多字段数据时优势明显。它不仅节省内存,还减少了key的数量,让数据管理更加清晰。
Hash操作命令详解
HSET/HGET 是Hash的基础操作。HSET可以设置单个或多个字段,HGET则获取指定字段的值。实际开发中,我倾向于使用HMSET一次性设置多个字段,减少网络往返次数。
HGETALL 会返回Hash的所有字段和值,但在字段很多时要谨慎使用。有次在生产环境误用HGETALL查询一个包含数百个字段的Hash,直接导致了短暂的性能瓶颈。
HINCRBY 提供了原子性的数值增减操作。在电商项目中,我们用它来管理商品库存,确保在高并发场景下库存数据的准确性。
HEXISTS 和 HDEL 分别用于判断字段存在性和删除字段。HLEN 快速返回字段数量,HKEYS/HVALS 则分别获取所有字段名或字段值。
HSCAN 对于大Hash特别重要。它支持增量式迭代,避免一次性获取大量数据造成的阻塞。这个命令救过我们好几次——当需要处理包含数万字段的配置Hash时,HSCAN让操作变得平滑可控。
命令的选择需要结合实际数据规模。小Hash可以随意使用HGETALL,大Hash则要考虑分批次操作。
Hash在用户信息存储中的实践应用
用户信息存储是Hash最典型的应用场景。在社交平台项目中,我们将用户基本信息存储在Hash中:
HMSET user:1001 name "张三" age 28 city "北京" profession "工程师"
这种方式比用多个String存储每个字段要高效得多。查询时可以根据需要获取部分字段,比如只获取用户名和头像,而不必读取完整的用户信息。
我负责过一个用户画像系统,Hash在这里发挥了重要作用。每个用户的标签体系用Hash存储,标签名为字段,标签权重为值。HINCRBY用于动态调整标签权重,HGETALL用于生成完整的用户画像。
另一个有趣的应用是购物车实现。每个用户的购物车是一个Hash,商品ID作为字段,购买数量作为值。添加商品使用HINCRBY,移除商品使用HDEL,查询购物车使用HGETALL。这种设计不仅直观,而且操作效率很高。
配置管理也是Hash的强项。我们将系统配置按模块存储在多个Hash中,修改配置只需更新特定字段,不会影响其他配置项。HSCAN命令让配置的批量导出和导入变得轻松。
Hash的灵活性让我印象深刻。有次需要实现一个简单的对象版本管理,我们用Hash存储不同版本的对象快照,字段名带上版本后缀,实现了轻量级的历史记录功能。
Hash就像Redis中的对象存储器,让结构化数据的处理变得优雅而高效。掌握好Hash的使用,能在很多场景下显著提升开发效率和系统性能。
Redis的集合类型家族为数据组织提供了多样化的选择。List像一条可以双向延伸的传送带,Set如同一个不允许重复的收纳盒,Sorted Set则像一份自动排序的成绩单。每种类型都有其独特的魅力和适用场景。
List类型及其队列应用
List在Redis中实现为双向链表,这意味着在列表两端进行操作的复杂度都是O(1)。这种特性让List天然适合实现队列结构。
LPUSH/RPUSH 和 LPOP/RPOP 构成了队列操作的基础。LPUSH和RPUSH分别从左右两端插入元素,LPOP和RPOP则从对应端弹出元素。在实际项目中,我们经常用LPUSH和RPOP组合实现先进先出队列,或者用LPUSH和LPOP实现后进先出栈。
我记得有个消息推送系统,使用List作为待发送消息的缓冲队列。生产者用LPUSH添加消息,多个消费者用BRPOP阻塞等待新消息。这种设计优雅地解决了生产消费的速度匹配问题,BRPOP的阻塞特性避免了消费者空转消耗资源。
LRANGE 命令可以获取列表的指定范围元素,这在分页场景中很有用。但要注意避免在大列表上使用LRANGE 0 -1这样的全量获取操作。有次排查性能问题,发现某个列表积累了数万条记录,而前端页面每次都要获取整个列表,导致响应缓慢。
LTRIM 是个很实用的命令,它可以保留列表的指定范围,自动删除范围外的元素。我们用它来实现固定长度的最新消息列表,始终保持只保留最近的100条记录。
List的阻塞操作 BLPOP/BRPOP 在实现任务调度时特别有价值。它们可以指定超时时间,在列表为空时阻塞连接,直到有新元素或超时。这种机制比轮询要高效得多。
Set类型与集合运算
Set存储不重复的字符串元素,内部实现是哈希表,这使得添加、删除、判断元素存在性的操作都是O(1)复杂度。
SADD 和 SREM 是基础的添加和删除操作。SISMEMBER 快速判断元素是否存在,这在权限校验、标签系统中经常用到。SMEMBERS 返回所有元素,但对于大集合要谨慎使用。
Set的真正威力在于集合运算。SINTER 求交集,SUNION 求并集,SDIFF 求差集。这些操作在社交关系、商品推荐等场景中非常实用。
我参与过一个电商项目的商品推荐系统,使用Set存储用户的浏览记录和购买记录。通过SINTER计算不同用户兴趣的交集,找出相似用户,再基于这些相似用户的购买记录生成推荐。
SRANDMEMBER 和 SPOP 都用于随机获取元素,但行为不同。SRANDMEMBER只是随机返回元素而不删除,SPOP则会移除并返回元素。在抽奖活动中,我们使用SPOP确保每个奖品只能被抽中一次。
Set的内存效率在处理大量不重复数据时表现突出。有次需要统计独立访客数,使用Set存储用户ID,然后通过SCARD获取集合基数,轻松得到UV数据。
Sorted Set有序集合应用
Sorted Set是Set的增强版本,每个元素都关联一个分数(score),元素按分数自动排序。这种结构在排行榜、优先级队列等场景中无可替代。
ZADD 添加带分数的元素,如果元素已存在则更新分数。ZRANGE 和 ZREVRANGE 分别按分数升序和降序获取元素。在游戏排行榜实现中,我们使用ZADD记录玩家分数,ZREVRANGE获取排名靠前的玩家。
分数可以是整数或浮点数,这为各种排序需求提供了灵活性。在新闻热度排序中,我们使用基于时间衰减和互动加权的复合分数,确保热门内容能够动态更新。
ZRANK 和 ZREVRANK 获取元素的排名位置。ZSCORE 获取元素的分数值。ZINCRBY 对元素分数进行原子性增减,这在实时更新排名的场景中特别有用。
我印象深刻的一个案例是延迟任务队列的实现。使用Sorted Set,任务执行时间作为分数,元素内容包含任务数据。定时任务通过ZRANGEBYSCORE获取到期的任务,处理完成后用ZREM移除。这种设计比轮询数据库要高效得多。
ZRANGEBYSCORE 和 ZREMRANGEBYSCORE 支持按分数范围操作,这在数据清理和时间窗口统计中很实用。比如只保留最近7天的活跃用户数据,自动清理过期数据。
三种类型对比与选择指南
选择合适的数据类型往往比优化代码更能提升系统性能。这三种集合类型各有侧重,理解它们的特性是做出正确选择的关键。
List适合顺序敏感、允许重复的场景。消息队列、最新列表、时间线这些需要保持元素顺序的用例都是List的主场。但List不支持直接按值查询,也不擅长去重。
Set的核心价值在于去重和集合运算。当需要存储不重复数据并进行交并差运算时,Set是最佳选择。标签系统、共同好友、独立统计这些场景都能发挥Set的优势。
Sorted Set在需要按权重排序时无可替代。排行榜、优先级队列、延迟任务这些需要排序能力的场景,Sorted Set提供了完美的解决方案。代价是比Set消耗更多内存,因为需要存储分数信息。
内存占用方面,List和Set相对较轻,Sorted Set由于存储分数信息会有额外开销。操作复杂度上,List的两端操作是O(1),但按索引访问是O(n);Set的基本操作都是O(1);Sorted Set的插入和范围查询是O(logN)。
有次重构一个用户行为分析系统,原本用List存储用户操作日志,但需要频繁去重统计。改为使用Set后,不仅简化了去重逻辑,统计效率也大幅提升。这个经历让我深刻体会到选择合适数据类型的重要性。
实际开发中,有时候需要组合使用这些类型。比如用Sorted Set维护排行榜,同时用Set存储详细数据。或者用List作为队列,用Set记录处理状态。这种组合往往能发挥各种类型的优势,实现更复杂的需求。
理解每种类型的特性和适用场景,就像工匠熟悉自己的工具一样重要。正确的选择能让代码更简洁,性能更优秀,维护更轻松。
掌握Redis基础数据类型后,真正的艺术在于如何将它们组合使用并优化性能。这就像学会了各种乐器的演奏技巧后,现在要学习如何编排交响乐。
数据类型组合使用策略
单一数据类型往往难以满足复杂业务需求,巧妙组合不同类型才能发挥Redis的真正威力。
String与Hash的搭档 在缓存用户信息时很常见。用String存储用户基础信息的序列化对象,同时用Hash存储经常需要单独更新的字段。比如用户昵称、头像这些频繁变更的数据放在Hash中,避免每次更新都要反序列化整个对象。
我参与过一个电商项目,商品详情页需要缓存大量数据。最初设计将所有信息序列化成String存储,结果每次更新库存都要重新序列化整个商品对象。后来改用Hash存储可变字段,String存储静态信息,性能提升了三倍以上。
Set与Sorted Set的配合 在社交推荐系统中效果显著。用Set存储用户的兴趣标签,用Sorted Set存储标签的热度分数。推荐时先通过Set交集找到相似用户,再用Sorted Set获取热门内容。
List作为消息队列 配合 Set记录处理状态 可以避免重复消费。生产者向List推送消息,消费者处理消息前先用SADD尝试将消息ID加入已处理集合,通过返回值判断是否重复。
这种组合思维让Redis从简单的键值存储升级为多功能数据平台。关键在于理解每种类型的优势,像搭积木一样构建解决方案。
内存优化与性能调优技巧
Redis性能优化的核心在于内存使用效率。不合理的数据结构设计会导致内存浪费和性能下降。
合理设置过期时间 是基础但重要的优化。为每个键设置TTL,避免数据无限增长。使用EXPIRE或SETEX命令,让Redis自动清理过期数据。
使用Hash代替多个String 能显著减少内存占用。当需要存储多个相关字段时,一个Hash比多个String键节省大量内存。Redis为小Hash提供了特殊编码优化。
有次优化一个会话存储系统,原本每个会话字段都存为独立的String键。改为Hash后,内存使用减少了40%,网络往返次数也大幅下降。
控制集合类型的规模 很重要。大集合的某些操作复杂度较高,可以考虑分片。比如将一个大Set拆分成多个小Set,通过客户端进行分片路由。
使用整数而不是字符串 存储数值。Redis对整数有特殊优化,存储和操作效率都更高。在可能的情况下,尽量使用整数作为值和分数。
监控内存碎片率 通过INFO memory命令。过高的碎片率会影响性能,可以通过重启或使用memory purge命令(如果支持)来整理内存。
避免大键和大量小键 两个极端。大键会导致操作阻塞,大量小键会增加内存开销。找到合适的平衡点需要根据具体业务特点调整。
常见问题排查与解决方案
实际使用中会遇到各种意料之外的问题,快速定位和解决这些问题是工程师的必备技能。
内存不足错误 是最常见的问题之一。首先分析内存使用情况,找出占用空间最大的键。使用redis-cli --bigkeys命令快速定位大键,或者使用MEMORY USAGE命令精确分析。
有次线上服务突然出现OOM,通过分析发现某个Sorted Set积累了数百万成员。原因是业务逻辑缺陷导致分数相同的元素无限增加。添加了数据量监控和自动清理机制后问题得到解决。
慢查询 影响用户体验。使用SLOWLOG GET命令查看慢查询日志,找出执行时间过长的命令。常见原因包括对大集合使用O(N)复杂度的操作,或者网络延迟导致的阻塞。
连接数过多 会导致资源耗尽。检查客户端连接池配置,确保连接及时释放。使用CLIENT LIST命令查看连接详情,找出异常连接。
数据不一致 在缓存场景中经常发生。确保缓存更新和数据库更新的原子性,或者采用先更新数据库再删除缓存的策略。设置合理的缓存失效时间,避免脏数据长期存在。
持久化问题 包括RDB和AOF的相关异常。监控持久化过程的状态,确保有足够的内存用于生成RDB快照。AOF文件过大会影响重启速度,定期进行AOF重写。
数据类型在企业级项目中的最佳实践
企业级应用对稳定性、性能、可维护性有更高要求,Redis的使用也需要遵循特定规范。
键命名规范 是基础中的基础。采用统一的命名空间,比如"业务模块:子模块:标识符"的格式。这便于管理、监控和批量操作。避免使用特殊字符和过长键名。
数据序列化方案 需要谨慎选择。JSON可读性好但体积较大,MessagePack或Protobuf更高效但要考虑兼容性。根据数据结构和访问模式选择合适的序列化方式。
我见过一个项目因为序列化方案选择不当导致CPU使用率居高不下。从JSON切换到MessagePack后,不仅网络传输量减少,序列化开销也大幅降低。
监控告警体系 必不可少。监控内存使用、连接数、命中率、慢查询等关键指标。设置合理的阈值,在出现异常时及时告警。使用Redis的INFO命令获取运行状态,或者集成专业的监控系统。
容灾备份策略 保障数据安全。定期备份RDB文件到安全位置,配置适当的AOF持久化级别。制定灾难恢复预案,定期演练恢复过程。
客户端使用规范 包括连接池配置、重试机制、超时设置等。避免在循环中执行Redis操作,尽量使用管道或批量操作。处理好连接异常和超时情况,确保服务的韧性。
容量规划 基于业务增长预测。提前预估数据量和访问量,规划好内存和网络资源。设置内存使用上限,避免单个Redis实例过大影响性能和可用性。
这些最佳实践来源于众多项目的经验总结。遵循它们能帮助构建更稳定、高效的Redis应用,让这个优秀的内存数据库真正成为系统的加速器而不是瓶颈。
Redis的强大不仅在于其丰富的数据类型,更在于如何根据业务需求灵活运用这些类型。优秀的Redis使用就像下棋,不仅要了解每个棋子的走法,更要懂得如何布局和配合。