1.1 什么是数据库索引及其重要性
想象一下在图书馆找一本书。没有索引的话,你需要从第一个书架开始逐个翻阅,直到找到目标。数据库索引就像图书馆的目录卡片,能让你快速定位到特定数据。
索引本质上是一种数据结构,通过建立字段值与数据位置的映射关系,大幅提升查询效率。一个设计良好的索引可能将查询时间从几秒缩短到几毫秒。我刚开始接触数据库时,曾在一个百万级数据表中执行查询,没有索引的情况下等了足足12秒,加上合适索引后,同样的查询瞬间完成。
索引的重要性体现在三个方面:查询加速、数据唯一性保证、排序优化。特别是在数据量增长的场景中,索引往往成为系统性能的关键决定因素。
1.2 MySQL索引类型详解
MySQL提供了多种索引类型,每种都有其适用场景。
B-Tree索引是最常见的类型,适用于全值匹配、范围查询和前缀匹配。它像一棵倒置的树,从根节点开始分支,直到叶子节点。B-Tree索引支持=、>、<、BETWEEN等操作符,是大多数情况下的默认选择。
Hash索引基于哈希表实现,仅支持精确匹配。它的查询速度极快,但不支持范围查询和排序。我记得在处理一个用户会话表时,Hash索引在等值查询中表现非常出色,但对于需要按时间范围筛选的需求就无能为力了。
Full-text索引专门用于全文搜索,能够高效处理文本内容的模糊匹配。它支持自然语言搜索和布尔搜索模式,对于文章、评论等文本字段的搜索特别有用。
空间索引用于地理数据查询,支持点、线、多边形等空间对象的快速检索。
1.3 索引的数据结构与工作原理
B-Tree结构是MySQL最核心的索引实现。它保持数据有序存储,每个节点包含多个键值和指针。查询时从根节点开始,通过比较键值确定下一步的查找方向,直到找到目标数据或确认数据不存在。
以查找数字57为例:根节点判断57在40-60区间,跳转到对应子节点;子节点继续判断,最终定位到包含57的叶子节点。这个过程通常只需要3-4次磁盘IO,而全表扫描可能需要成千上万次。
索引的工作原理可以比作书本的目录。你想找某个主题的内容,不会一页页翻书,而是先查目录找到对应页码。数据库引擎也是先查索引找到数据位置,再直接读取目标数据。
1.4 适合创建索引的场景分析
不是所有字段都适合创建索引。一般来说,满足以下条件的字段需要考虑索引:
经常出现在WHERE子句中的字段,特别是等值查询条件。比如用户表的手机号、邮箱字段,这些字段查询频率高且通常需要快速响应。
外键关联字段通常需要索引。当执行表连接查询时,索引能显著提升连接效率。我遇到过的一个性能问题就是缺少外键索引,导致两个表的JOIN操作异常缓慢。
需要排序或分组的字段。ORDER BY和GROUP BY操作如果能利用索引,可以避免额外的排序开销。
高选择性的字段更适合索引。选择性指不同值的数量与总记录数的比例。比如性别字段只有两个可能值,索引效果就不理想;而身份证号几乎每个值都唯一,索引效果极佳。
需要谨慎创建索引的场景包括:写多读少的表、小数据量表、更新频繁的字段。索引在提升查询速度的同时,也会增加存储空间和写操作的开销。
2.1 索引的创建、修改与删除操作
创建索引就像给数据库配备导航系统。最基本的创建语句很简单:CREATE INDEX idx_name ON table_name(column_name)。但实际工作中需要考虑更多细节。
复合索引的创建需要特别注意字段顺序。比如CREATE INDEX idx_user ON users(last_name, first_name),这个索引能支持(last_name)查询、(last_name, first_name)查询,但无法支持单独的first_name查询。字段顺序应该按照查询频率和选择性来排列,把最常用、选择性最高的字段放在前面。
唯一索引通过CREATE UNIQUE INDEX创建,它既保证查询效率,又确保数据唯一性。用户表的邮箱字段就很适合创建唯一索引。我记得有个项目因为漏掉了唯一索引,导致出现了重复用户数据,后续清理花费了不少精力。
修改索引通常意味着先删除再重建。使用DROP INDEX index_name ON table_name删除不需要的索引,然后创建新的索引。在线业务中执行这类操作需要谨慎,最好在业务低峰期进行,避免影响正常服务。
2.2 索引性能分析与EXPLAIN使用
EXPLAIN是分析查询性能的必备工具。在SQL语句前加上EXPLAIN,就能看到MySQL的执行计划。这个功能非常实用,能帮你理解数据库如何执行你的查询。
看EXPLAIN输出要关注几个关键字段:type列显示访问类型,从最优到最差大致是const、eq_ref、ref、range、index、ALL。理想情况下应该避免看到ALL,这表示全表扫描。possible_keys显示可能使用的索引,key显示实际使用的索引。
rows列估计需要检查的行数,这个数字越小越好。Extra列提供额外信息,比如Using index表示使用了覆盖索引,Using temporary表示需要创建临时表,Using filesort表示需要额外排序。
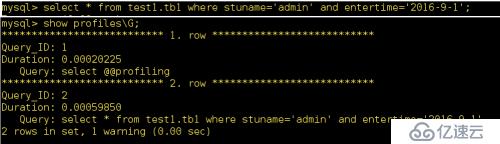
我曾经用EXPLAIN分析一个慢查询,发现虽然创建了索引,但查询条件的数据类型不匹配导致索引失效。将字符串条件的引号去掉后,查询时间从2秒降到了0.01秒。这种细节往往容易被忽略。
2.3 常见索引优化技巧与最佳实践
索引优化是个细致活。覆盖索引是个很好的技巧,当索引包含查询所需的所有字段时,数据库可以直接从索引获取数据,避免回表操作。比如SELECT id, name FROM users WHERE age > 18,如果索引包含(id, name, age),查询效率会很高。
前缀索引适合文本字段,特别是长度较大的VARCHAR字段。CREATE INDEX idx_email_prefix ON users(email(10))只对邮箱的前10个字符建立索引,既能节省空间,又能保证大部分场景下的查询效率。
避免在索引列上使用函数或表达式。WHERE YEAR(create_time) = 2023无法使用create_time字段的索引,改成WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31'就能利用索引了。
索引数量不是越多越好。每个额外的索引都会增加写操作的开销,因为每次INSERT、UPDATE、DELETE都需要更新所有相关索引。一般来说,表的索引数量控制在5个以内比较合理。
2.4 索引维护与监控管理
索引需要定期维护才能保持良好性能。ANALYZE TABLE命令更新索引统计信息,帮助优化器做出更好的执行计划。统计信息不准确可能导致优化器选择错误的索引。
碎片整理也很重要。随着数据增删改,索引会产生碎片,降低查询效率。OPTIMIZE TABLE或者ALTER TABLE table_name ENGINE=InnoDB可以重建表并整理索引碎片。对于大表,可以在从库上执行然后切换主从。
监控索引使用情况可以通过SHOW INDEX FROM table_name查看索引基数等信息。performance_schema和sys库提供了更详细的索引使用统计,能够看到哪些索引真正被使用,哪些是"僵尸索引"。
设置合适的监控告警很实用。可以监控索引大小增长、索引扫描比例等指标。当发现全表扫描比例过高时,可能意味着需要增加新的索引。这种主动发现问题的方式比等到用户投诉要好得多。