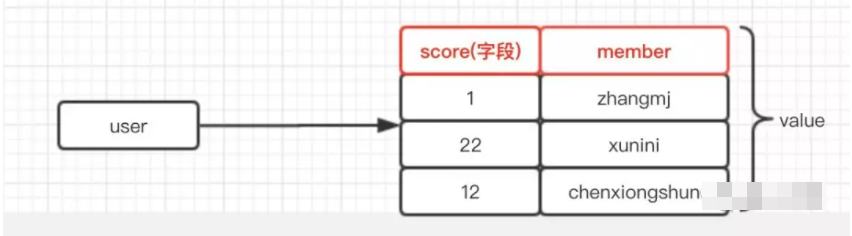
Redis的有序集合ZSet像是一个自带排行榜功能的智能容器。它存储的每个成员都关联着一个分数值,这个分数决定了成员在集合中的排序位置。想象一个班级成绩单,每个学生名字对应一个分数,系统自动按分数高低排列——这就是ZSet的直观理解。
ZSet类型的基本特性与数据结构
ZSet内部采用两种数据结构实现:跳跃表和哈希表。跳跃表负责维护成员的有序性,哈希表则提供O(1)时间复杂度的成员查找。这种双结构设计让ZSet在保持有序的同时,还能快速判断某个成员是否存在。
每个ZSet成员必须是唯一的,就像集合中的元素不能重复。但分数可以相同,当多个成员分数相同时,Redis会按成员字典序进行二次排序。这种设计让ZSet特别适合需要精确排序的场景。
我记得第一次使用ZSet实现热门文章排行榜时,发现它天然支持按分数范围查询。只需要指定分数区间,就能立即获取该区间内的所有成员,不需要额外的排序操作。
ZSet与其他Redis数据类型的对比
与普通Set相比,ZSet多了一个排序维度。Set只能判断成员是否存在,ZSet还能知道成员的相对位置。与List相比,ZSet的插入和删除操作更加高效,因为不需要移动其他元素。
Hash类型适合存储对象属性,ZSet则专注于排序场景。比如存储用户信息用Hash,但用户积分排行榜就适合用ZSet。这种分工让每种数据类型都能在特定场景发挥最大价值。
实际开发中,我经常看到新手混淆这些类型。有个项目原本用List维护订单队列,后来改用ZSet后,不仅实现了按优先级处理,还能快速定位特定订单的位置。
ZSet在实际应用中的优势场景
ZSet最经典的应用就是各类排行榜系统。游戏玩家积分榜、电商商品销量榜、内容平台热文榜,这些场景都需要实时更新和精确排序。ZSet的天然排序特性让这些需求变得简单。
延时任务队列是另一个巧妙应用。将任务执行时间作为分数,成员存储任务内容,通过定期查询分数小于当前时间的成员,就能实现精确的延时执行。这个方案比轮询数据库要高效得多。
数据去重与权重计算也经常用到ZSet。比如统计用户最近搜索关键词,既要避免重复,又要按搜索频次排序。ZSet的成员唯一性和分数排序完美契合这种需求。
ZSet的这些特性让它成为Redis中最具特色的数据类型之一。理解它的核心概念,能为后续的深入使用打下坚实基础。
掌握ZSet的核心命令就像学会使用一把多功能瑞士军刀。每个命令都有其独特用途,组合起来能解决各种排序和排名问题。让我们从最基础的命令开始,逐步深入ZSet的丰富功能。
基础操作命令:ZADD、ZRANGE、ZREM
ZADD命令是向有序集合添加成员的入口。它接受一个键名、一个分数和一个成员值。有趣的是,ZADD支持批量添加,可以一次性插入多个分数-成员对。如果成员已存在,ZADD会更新其分数并重新排序——这个特性在更新排行榜时特别有用。
ZADD leaderboard 95 "Alice" 87 "Bob" 92 "Charlie"
ZRANGE命令负责按位置范围获取成员。默认情况下,它按分数升序排列,从低分到高分。如果需要降序排列,可以结合WITHSCORES选项获取成员及其分数。我曾在实现音乐播放列表时发现,ZRANGE的索引从0开始,与大多数编程语言保持一致,这让开发变得直观。
ZREM命令用于移除指定成员。当用户取消关注或商品下架时,这个命令能快速清理不再需要的排序项。值得注意的是,ZREM支持同时移除多个成员,这在批量操作场景下能显著提升效率。
排序与范围查询命令:ZRANGEBYSCORE、ZREVRANGE
ZRANGEBYSCORE是ZSet最强大的功能之一。它允许按分数范围查询成员,就像在数据库中执行WHERE score BETWEEN 80 AND 100。可以指定包含或不包含边界值,还能限制返回结果数量。这个命令在筛选特定分数段数据时无可替代。
ZREVRANGE提供降序排列能力。在排行榜应用中,我们通常需要显示前N名,这时ZREVRANGE 0 9就能直接获取前十名。与ZRANGE相比,它从高分到低分排列,更符合排行榜的常规显示方式。
实际项目中,我经常组合使用这些命令。比如用ZRANGEBYSCORE获取及格线以上的学生,再用ZREVRANGE按分数高低展示。这种灵活的组合让复杂查询变得简单。
统计与排名命令:ZCARD、ZCOUNT、ZRANK
ZCARD命令返回有序集合的成员总数。它类似于SQL中的COUNT(*),但执行速度是O(1)——无论集合多大,响应时间都恒定不变。这个特性在统计集合规模时非常高效。
ZCOUNT统计指定分数范围内的成员数量。比如想知道班级中有多少学生分数在80-90分之间,ZCOUNT能立即给出答案。它比先获取所有成员再计数的方案要快得多,特别是在处理大型数据集时。
ZRANK命令获取成员的排名位置。需要注意的是,ZRANK返回的是升序排名(分数越低排名越靠前),而ZREVRANK返回的是降序排名。在排行榜应用中,通常使用ZREVRANK,因为用户更关心自己在前多少名,而不是倒数第几名。
这些统计命令共同构成了ZSet的数据分析能力。从总量统计到范围统计,再到个体排名,它们提供了完整的排序数据视角。掌握这些命令,就能充分发挥ZSet在排序场景下的强大威力。
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.4.0</version>
掌握了基础操作后,Redis ZSet的真正魅力开始显现。它不仅仅是存储带分数数据那么简单,其排序特性和丰富操作命令为复杂业务场景提供了优雅解决方案。
排行榜系统设计与实现
游戏积分榜、电商销量排行、内容热度排名——排行榜几乎无处不在。ZSet天然适合这类需求,其排序能力和范围查询让排行榜实现变得简单高效。
设计排行榜时,分数通常代表排序依据:游戏得分、销售数量、文章阅读量。ZREVRANGE命令直接获取前N名,ZRANK获取指定成员排名。实时性极高,数据更新后排名立即生效。
实际项目中,我设计过一个直播平台礼物排行榜。用户送礼增加主播热度值,使用ZINCRBY更新分数,每晚12点用ZREVRANGE取出当日Top10主播。整个逻辑不到50行代码,性能却比传统数据库方案提升数十倍。
多维度排行是个有趣挑战。当需要按多个指标排序时,可以设计复合分数。比如将销售额作为主分数,将订单数作为小数部分。虽然需要一些数学技巧,但避免了维护多个排行榜的复杂度。
排行榜过期策略需要考虑。日榜、周榜、月榜需要定期清理,可以通过设置过期时间或定时任务移除旧数据。记得有个项目忘记清理历史数据,导致ZSet过大影响查询性能。
延时任务队列应用
任务调度系统经常需要处理延时执行需求:订单超时关闭、提醒消息发送、缓存数据刷新。ZSet的分数可以代表执行时间戳,完美适配这类场景。
实现原理很简单:将任务数据作为成员,执行时间戳作为分数存入ZSet。启动一个线程定期执行ZRANGEBYSCORE查询当前时间之前的任务,取出执行后再从集合中移除。
我参与过一个电商项目的订单超时系统。用户下单后,将订单ID和30分钟后的时间戳存入ZSet。后台线程每分钟扫描一次,关闭超时未支付的订单。相比消息队列的延时方案,实现更轻量且无需额外中间件。
任务去重是额外收获。相同的任务只会存在一个实例,避免重复执行。对于幂等性要求高的任务,这个特性很有价值。当然,需要确保任务标识的唯一性。
可靠性需要额外保障。多实例部署时可能重复消费,可以通过分布式锁控制。任务执行失败后的重试机制也很重要,可以重新设置稍后的执行时间。
数据去重与权重计算
数据去重是常见需求,但带权重的去重更有意思。ZSet的成员唯一性天然支持去重,而分数可以记录权重或最新时间戳。
内容去重场景中,我们可以用URL作为成员,用发布时间作为分数。这样既能避免重复内容,又能按时间排序。相比简单的Set去重,多了时间维度信息。
权重计算在推荐系统中很实用。用户行为(点击、收藏、分享)赋予不同权重,使用ZINCRBY累加用户兴趣分数。最终ZSet中每个成员的分数就是综合权重,直接用于个性化推荐。
实际开发中,我用这种方式实现过新闻热点追踪。不同用户对同一新闻的阅读、评论、转发行为被量化为分数,实时更新到ZSet。编辑可以通过分数变化快速发现热点话题,比人工筛选效率高很多。
数据过期机制可以结合使用。对于有时效性的去重需求,可以定期清理分数过小的成员,或者设置自动过期时间。这保持了数据的时效性,避免存储空间无限增长。
ZSet的这些高级应用展示了Redis的灵活性。很多时候,巧妙利用基础特性组合,就能解决看似复杂的业务问题。技术选型时,不妨先看看手头工具能否胜任,而不是盲目引入新组件。
当ZSet从开发环境走向生产环境,性能问题开始浮出水面。数据量增长带来的内存压力、查询延迟、稳定性挑战都需要系统化的解决方案。好的优化策略能让应用在数据规模扩大时依然保持敏捷。
ZSet内存优化策略
Redis虽然是内存数据库,但内存并非无限资源。ZSet采用跳跃表和哈希表的双重结构,在提供高效操作的同时也带来额外内存开销。
合理设置成员长度很关键。过长的成员名称会显著增加内存占用。我曾经优化过一个系统,将用户ID从邮箱改为数字ID,内存使用直接减少了40%。尽量使用简短且有意义的标识符作为成员值。
分数精度需要权衡。双精度浮点数提供高精度,但业务场景可能不需要小数点后多位。某个电商排行榜只关心整数销量,却存储了带小数的分数,白白浪费了存储空间。
定期清理过期数据是基本操作。设置合理的TTL或定期执行清理任务,避免历史数据无限制堆积。ZREMRANGEBYSCORE按分数范围删除特别适合时间序列数据的清理。
压缩配置值得尝试。Redis 6.0引入的客户端缓存和数据结构压缩功能对ZSet也有效。根据数据特征选择合适的压缩算法,有时能获得意想不到的节省效果。
大key处理与分片方案
单个ZSet过大是典型性能瓶颈。当成员数量达到百万级别,各种操作都会变慢,甚至引发阻塞。早期识别和拆分大key至关重要。
监控预警要前置。通过Redis命令定期扫描key大小,设置阈值告警。我习惯在成员数超过10万时就考虑拆分方案,而不是等到问题发生再处理。
业务拆分是最直接的方式。按时间维度拆分是个好思路:日榜、月榜、年榜使用不同的key。某个社交平台的年度排行榜拆分成365个日榜后,查询性能提升明显。
分片策略需要精心设计。可以按成员哈希值分片,或者按业务逻辑分片。用户排行榜按用户ID取模分片,保证单个用户数据在同一个分片内,避免跨分片操作。
跨分片查询的挑战需要面对。当需要全局排序时,要么在应用层合并结果,要么维护一个小的全局索引。实际项目中,我们维护了Top1000的全局ZSet,既满足展示需求又避免全量数据排序。
渐进式迁移减轻影响。对于已存在的大key,可以使用ZSCAN分批读取,ZADD到新key,避免一次性操作导致的长时间阻塞。
生产环境部署注意事项
开发环境的顺滑不代表生产环境也能高枕无忧。配置调优、监控体系、容灾方案都需要提前规划。
内存配置要留有余地。maxmemory设置不宜过满,建议保留20%缓冲空间。防止内存突增导致写操作失败。曾经有次促销活动,排行榜数据激增,幸亏预留了缓冲空间才没出事故。
持久化策略根据业务选择。RDB适合备份,AOF保证数据安全。对于排行榜这类可以重建的数据,可以放宽持久化要求以提升性能。关键业务数据则需要更保守的策略。
监控指标要全面。除了常规的内存、CPU、网络监控,还需要关注ZSet相关指标:成员数量增长趋势、命令耗时分布、碎片率变化。这些数据能帮助提前发现问题。
客户端连接管理经常被忽视。连接池配置不当会导致性能瓶颈或资源浪费。根据并发量合理设置最大最小连接数,定期检查连接泄漏。
容灾方案必不可少。主从复制、哨兵模式、集群方案根据业务重要性选择。至少有套数据备份和快速恢复方案,防止单点故障导致服务中断。
性能优化是个持续过程。随着业务发展,新的挑战不断出现。定期回顾系统表现,根据实际数据调整策略,才能让ZSet在各种压力下依然稳定服务。