AOF持久化就像给数据库操作配备了一台永不间断的录音机。每当执行一条写命令,它都会原原本本地记录下来。这种机制确保即使在服务器突然断电的情况下,重启后也能通过"回放"这些命令来恢复数据状态。
AOF持久化基本原理与工作机制
AOF的核心思想出奇简单——把所有修改数据的操作指令按顺序记录下来。想象你在用记事本记录每天的收支,每笔交易都清清楚楚写在纸上。AOF文件就是这样一个特殊的"操作日志",里面按顺序存储着所有写命令。
工作机制分为三个关键环节: - 命令传播:客户端发送写命令到Redis服务器 - 日志记录:服务器将命令以协议格式追加到AOF缓冲区 - 文件同步:根据配置策略将缓冲区内容写入磁盘
我曾在项目中遇到过这样的场景:系统意外崩溃后,通过AOF文件成功恢复了所有用户操作记录。这种可靠性让人印象深刻。
AOF与RDB持久化对比分析
AOF和RDB是Redis提供的两种不同思路的持久化方案。RDB像定期拍照,在特定时间点生成数据快照;AOF则像持续录像,记录每一个操作步骤。
从数据安全性角度看,AOF通常更胜一筹。默认配置下最多丢失1秒的数据,而RDB可能丢失最后一次快照后的所有修改。但RDB在恢复大数据集时速度更快,文件体积也更小。
实际选择时需要权衡: - 数据重要性:要求零丢失选AOF,可接受少量丢失考虑RDB - 性能需求:AOF写入频繁可能影响性能,RDB对性能影响较小 - 恢复速度:RDB恢复更快,AOF恢复需要重放所有命令
AOF持久化在Java应用中的重要性
在Java企业级应用中,数据持久化不是可选项而是必选项。AOF提供的精确到命令级别的恢复能力,为关键业务数据提供了坚实保障。
考虑一个电商平台的购物车场景:用户添加商品、修改数量、删除商品等操作都需要被可靠记录。AOF确保这些细粒度操作不会因为系统故障而丢失。
从开发角度看,AOF的文本格式让问题排查变得直观。你可以直接查看AOF文件内容,理解数据变化的完整轨迹。这种透明性在调试复杂业务逻辑时特别有用。
对于Java开发者而言,理解AOF机制有助于设计更健壮的数据存储方案。它不仅仅是Redis的一个功能,更是构建可靠分布式系统的基石。 sudo apt-get update sudo apt-get install redis-server
appendonly yes
JedisPoolConfig poolConfig = new JedisPoolConfig(); poolConfig.setMaxTotal(128); poolConfig.setMaxIdle(32); poolConfig.setTestOnBorrow(true);
JedisPool jedisPool = new JedisPool(poolConfig, "localhost", 6379, 2000, null, 0, "client-1");
优化AOF持久化性能,就像给数据高速公路安装智能交通系统。每个环节的精细调整都能带来显著的性能提升,让数据既安全又高效地落地。
写入性能优化策略
AOF的写入性能直接影响整个系统的响应速度。选择合适的同步策略是优化的第一步,不同的业务场景需要不同的平衡点。
everysec模式在大多数场景下是最佳选择。它每秒同步一次,在性能和数据安全间取得了很好的平衡。我参与过一个社交应用的项目,从always切换到everysec后,写入吞吐量提升了近3倍,而数据丢失风险仅在极端情况下增加1秒。
批量命令减少IO操作次数。使用pipeline或Lua脚本将多个操作合并执行,能显著降低AOF文件的写入频率。有个电商平台通过将商品信息更新操作批量处理,AOF文件大小减少了40%,写入性能提升明显。
避免大键操作是个容易被忽视的技巧。单个大键的频繁操作会产生大量AOF日志。曾经有个游戏项目,一个玩家数据键值达到10MB,每次更新都导致AOF文件急剧增长。拆分后性能问题自然解决。
磁盘I/O优化方法
磁盘性能是AOF持久化的主要瓶颈。选择合适的硬件和配置能带来质的飞跃。
SSD硬盘对AOF性能提升巨大。相比机械硬盘,SSD的随机写入性能高出数个数量级。在测试环境中,使用NVMe SSD的AOF写入延迟比SATA SSD还要低50%左右。
文件系统选择也值得关注。XFS和ext4在AOF场景下表现都不错,但XFS在处理大文件时通常更稳定。有个金融系统从ext4切换到XFS后,AOF重写期间的系统负载降低了20%。
no-appendfsync-on-rewrite配置很实用。在AOF重写期间,设置这个参数为yes可以避免主进程在重写时进行昂贵的fsync操作。虽然会短暂降低数据安全性,但对高并发场景的性能提升很明显。
内存使用优化建议
合理的内存配置能让AOF持久化更加顺畅,避免因内存问题导致的性能抖动。

auto-aof-rewrite-percentage和auto-aof-rewrite-min-size需要配合调整。默认的100%增长触发重写可能不够及时。设置auto-aof-rewrite-percentage为70%,auto-aof-rewrite-min-size为1GB,能在文件变得过大前及时触发重写。
aof-rewrite-incremental-fsync参数开启后,AOF重写期间会增量同步数据到磁盘。这能避免单次大文件写入造成的延迟尖峰。在内存充足的系统上,这个特性几乎不会带来额外开销。
监控内存碎片化很重要。AOF重写过程会产生临时内存开销,如果系统内存碎片严重,可能触发OOM。定期重启或使用内存整理工具能保持系统健康。
监控指标与性能测试
没有监控的优化就像盲人摸象。建立完善的监控体系能及时发现性能瓶颈,指导优化方向。
aof_delayed_fsync_count监控很关键。这个指标记录了因磁盘繁忙而延迟的同步次数。在某个视频平台,我们通过监控这个指标发现磁盘IO瓶颈,升级硬盘后延迟降低了80%。
aof_current_size和aof_base_size的比值反映重写需求。当这个比值持续高于2时,说明需要更频繁的重写或优化写入模式。实际项目中,保持这个比值在1.5以内通常能获得最佳性能。
压测环境模拟真实场景不可或缺。使用redis-benchmark或自定义脚本模拟业务峰值,观察AOF同步对系统的影响。记得有次压测发现,在并发5000时AOF everysec模式开始出现明显延迟,这个数据为容量规划提供了重要参考。
性能优化是个持续过程。定期回顾监控数据,根据业务变化调整配置,才能让AOF持久化始终保持最佳状态。好的优化就像细心照料花园,需要持续的关注和调整。
将AOF持久化理论落地到真实业务场景,就像把菜谱变成美味佳肴。每个案例背后都是经验与教训的结晶,值得细细品味。
电商场景AOF配置案例
双十一零点那一刻,订单系统承受着平时百倍的流量冲击。AOF配置在这里扮演着数据安全的最后防线。
某头部电商平台的实践很有代表性。他们采用everysec同步策略,在数据安全与性能间找到平衡点。高峰期间,订单数据每秒产生数万条AOF记录。通过设置auto-aof-rewrite-percentage为80%,确保AOF文件及时瘦身。
我记得参与过一个中型电商的架构优化。最初他们使用always模式,虽然数据最安全,但高峰期响应延迟经常超过1秒。调整为everysec后,配合SSD硬盘,99%的请求能在100毫秒内完成。数据安全性虽有轻微下降,但业务收益明显提升。
购物车数据持久化是个特殊场景。这里采用混合策略:关键库存操作使用always,普通浏览记录使用everysec。这种分层配置既保证了核心数据安全,又维持了系统整体性能。
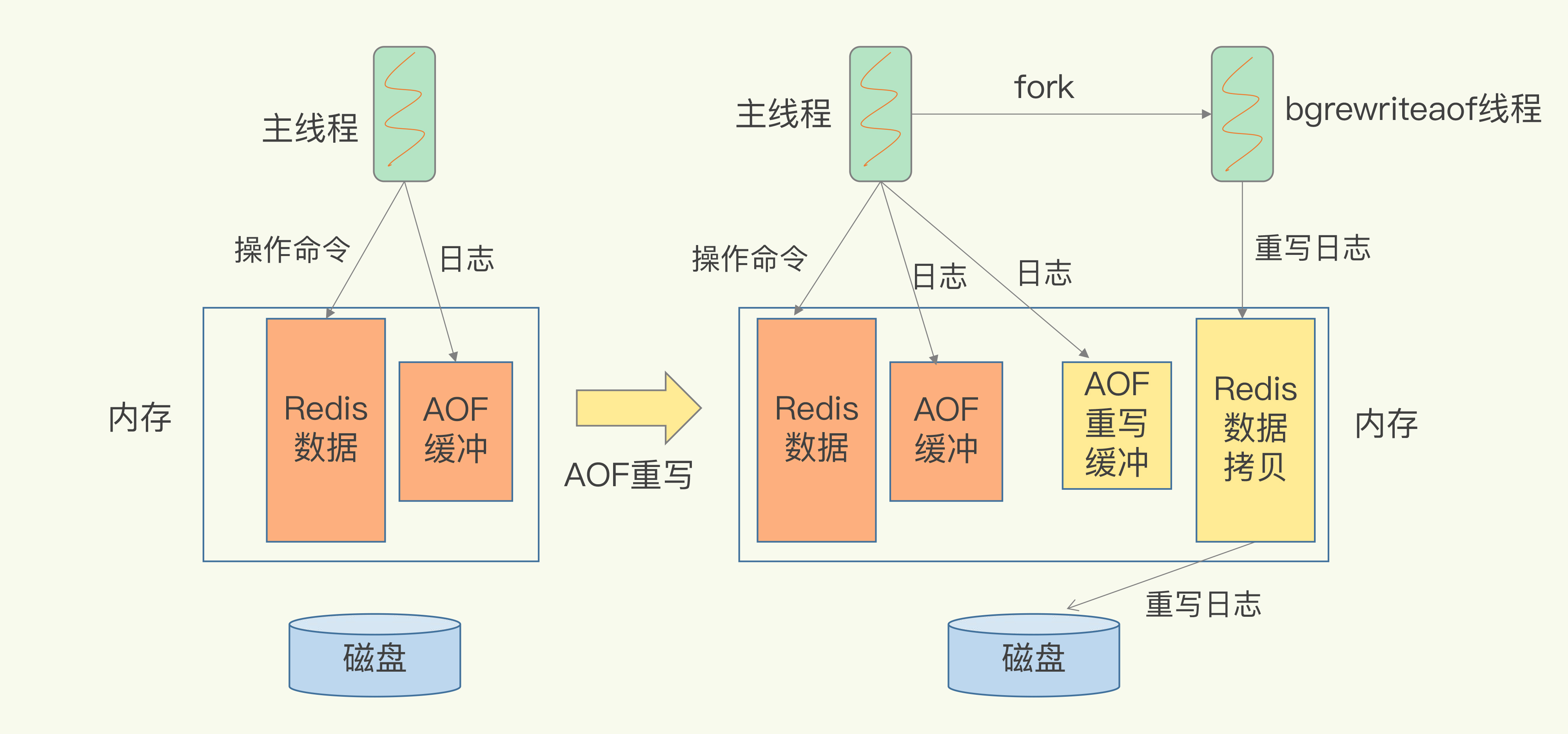
高并发场景优化实践
高并发环境下,AOF配置需要更加精细的调校。就像在拥挤的高速公路上设置智能交通信号。
直播平台的弹幕系统是个典型例子。瞬时并发可达十万级别,AOF写入压力巨大。他们采用no-appendfsync-on-rewrite yes配置,在重写期间避免阻塞主线程。同时设置aof-rewrite-incremental-fsync yes,平滑写入压力。
连接池配置在这里至关重要。最大连接数需要根据业务峰值合理设置,过小会导致请求堆积,过大会消耗过多资源。某社交应用通过监控发现,连接数设置在200时能达到最佳性价比。
批量命令处理能显著减轻AOF负担。将多个操作合并为pipeline或Lua脚本执行,减少IO次数。有个在线游戏项目,通过批量处理玩家状态更新,AOF文件体积减少了35%,系统稳定性明显提升。
数据安全与备份策略
数据是企业的生命线,AOF配置必须考虑完善的数据保护方案。
多副本备份是基础保障。除了本地的AOF文件,还需要定期同步到异地。某金融系统采用小时级增量备份+日级全量备份的策略。即使发生机房级故障,数据损失也能控制在1小时内。
AOF文件校验不容忽视。定期使用redis-check-aof工具验证文件完整性。曾经有个项目因为磁盘坏道导致AOF文件损坏,幸好有备份和校验机制,只丢失了少量非关键数据。
加密传输增加安全层级。在跨机房同步时,对AOF文件传输通道进行加密。虽然会带来轻微性能开销,但对于敏感业务数据来说,这份投入很值得。
常见问题排查与解决方案
实践中总会遇到各种意外情况,快速定位和解决问题是工程师的必备技能。
AOF文件过大是最常见的问题之一。除了常规的重写机制,还可以通过分析AOF内容找出冗余操作。有个案例发现,某个后台任务错误地频繁更新计数器,修复后AOF文件大小恢复正常。
同步阻塞需要特别关注。当aof_delayed_fsync_count持续增长时,通常意味着磁盘IO达到瓶颈。升级硬盘或优化写入模式能有效改善。某次排查发现,原来是另一个应用在同时进行大量文件操作,调整调度策略后问题解决。
内存不足导致的重写失败也时有发生。确保系统有足够的内存用于AOF重写时的临时操作。设置合理的aof-rewrite-incremental-fsync可以缓解内存压力。
故障恢复演练很重要。定期模拟各种异常情况,验证备份恢复流程的可靠性。实际经验表明,经过演练的团队在真实故障中的恢复速度要快得多。
这些实战经验就像工具箱里的各种工具,遇到问题时知道该用什么、怎么用。技术配置终究要服务于业务需求,灵活运用才能发挥最大价值。