1.1 什么是Redis缓存及其在Java应用中的重要性
Redis本质上是一个开源的键值存储系统。它把数据保存在内存中,这让读写速度变得飞快。想象一下从书架上拿书和从桌上拿书的区别,Redis就是那张离你最近的桌子。
在Java应用里,Redis经常扮演缓存的角色。我记得有个电商项目,商品详情页每次都要查询数据库,用户多了系统就开始卡顿。引入Redis后,热门商品数据直接缓存起来,页面加载时间从2秒降到了200毫秒。这种速度提升在实际业务中几乎能决定用户体验的成败。
缓存不仅仅是为了快。它还能帮数据库分担压力,避免频繁的IO操作。当大量请求涌来时,Redis就像一道缓冲带,保护后端系统不被冲垮。对于Java开发者来说,掌握Redis几乎成了必备技能。
1.2 Redis缓存策略的基本类型与特点
常见的缓存策略主要有几种。LRU(最近最少使用)会优先淘汰最久未被访问的数据,这很符合“用进废退”的直觉。LFU(最不经常使用)则关注访问频率,经常被访问的数据更可能留下来。
TTL(生存时间)策略给每个数据设置过期时间,像食品的保质期一样直接明了。还有随机淘汰策略,虽然听起来随意,但在某些场景下效果出奇的好。
每种策略都有其适用场景。LRU适合大多数常规需求,LFU在热点数据明显的业务中表现更好。TTL则适用于数据有明确时效性的情况,比如验证码、会话信息。选择时需要考虑数据访问模式,没有绝对的最优解。
1.3 选择合适缓存策略的关键因素
数据特性是首要考虑因素。高频变化的数据可能不适合长时间缓存,静态数据则可以放心缓存。数据大小也很关键,大对象会占用更多内存,需要更谨慎地管理。
业务场景决定了策略的偏向。读多写少的场景可以大胆缓存,写操作频繁的系统则需要更精细的控制。一致性要求高的业务必须考虑缓存与数据库的同步问题。
资源限制往往被忽略。内存大小直接影响能缓存多少数据,网络带宽影响缓存同步的效率。我曾经遇到一个案例,团队选择了复杂的缓存策略,结果因为内存不足频繁触发淘汰,反而降低了性能。
成本效益分析也很重要。引入缓存带来的性能提升是否值得额外的维护成本?这个问题没有标准答案,需要根据具体业务来权衡。
2.1 Java连接Redis的常用客户端配置
Java生态中有几个主流的Redis客户端。Jedis算是最老牌的选择,API直接简单,同步调用模式让初学者很容易上手。Lettuce则是后起之秀,基于Netty的异步特性在高并发场景下表现更出色。
配置连接池是个技术活。最大连接数设得太小会导致请求排队,设得太大又浪费资源。我通常建议从50个连接开始测试,根据实际负载慢慢调整。超时时间也需要仔细考量,设置太短会在网络波动时频繁报错,太长又会掩盖真正的系统问题。
记得有次排查线上问题,发现某个服务的Redis响应时间偶尔会飙升到几秒。最后发现是连接池的最大等待时间设置过长,请求在队列里堆积了很久才超时。把maxWaitMillis从默认的-1改为合理的2000毫秒后,问题就消失了。
Spring Data Redis让配置变得更简单。通过几个属性就能完成大部分设置,还提供了连接工厂的自动配置。这种便利性确实让开发效率提升不少。
2.2 缓存穿透、缓存击穿与缓存雪崩的预防策略
这三个概念经常被混淆,但它们对应着不同的场景和解决方案。
缓存穿透指的是查询一个根本不存在的数据。恶意攻击者可能会故意查询不存在的key,导致请求直接打到数据库。布隆过滤器是个不错的解决方案,它在查询Redis之前先做一层过滤。也可以考虑缓存空值,给不存在的key设置一个很短的过期时间。
缓存击穿发生在热点key过期瞬间。大量请求同时发现缓存失效,集体涌向数据库。互斥锁是个经典解法,只让一个请求去加载数据,其他请求等待。也可以考虑逻辑过期,不设置实际的TTL,而是通过额外字段判断是否需要更新。
缓存雪崩更可怕,大量key在同一时间失效。我曾经见过一个系统因为缓存都设置了相同的过期时间,在某个整点集体失效,数据库瞬间被打垮。解决方案很简单,给不同的key加上随机过期时间偏移量,让失效时间分散开。
这些问题的核心思路其实很一致:保护后端系统,避免瞬时压力。
2.3 缓存数据一致性与过期策略管理
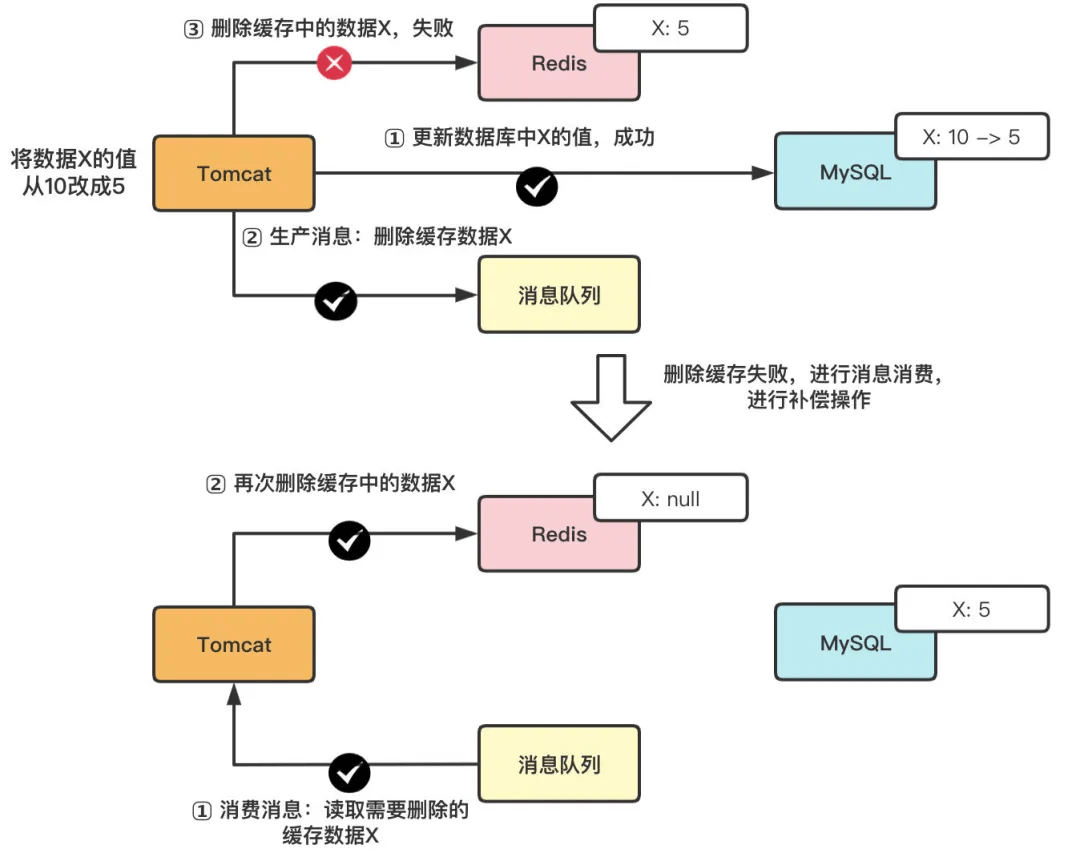
缓存和数据库的一致性是个永恒的话题。先更新数据库再删除缓存是最常用的做法,虽然理论上存在极短时间的不一致,但实际影响通常可以接受。
有些场景需要更强的一致性。比如金融业务的余额查询,这时候可能需要更复杂的方案。双写策略要求同时更新缓存和数据库,但要处理好事务问题。或者使用数据库的binlog监听,通过canal这样的工具异步更新缓存。
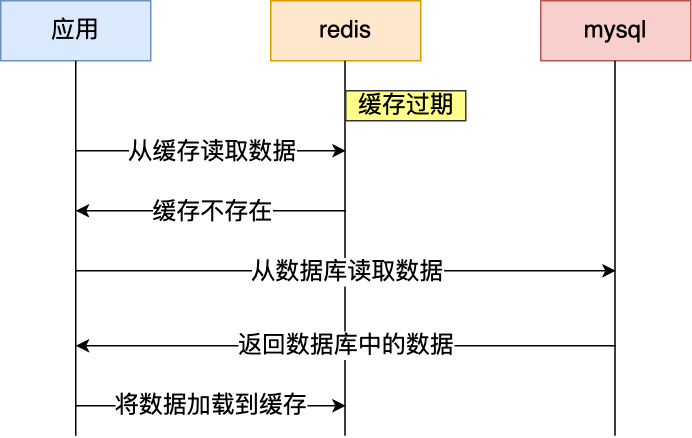
过期策略的管理需要智慧。TTL设置太短会频繁回源查询,设置太长又可能导致数据陈旧。我觉得可以借鉴CDN的思路,设置一个基础TTL,再配合主动更新机制。当数据发生变化时主动刷新缓存,而不是被动等待过期。
监控缓存的命中率很重要。低于80%可能意味着策略需要调整,太高又可能说明缓存的数据不够新。找到平衡点需要持续观察和优化。
2.4 使用Spring Boot集成Redis缓存的最佳实践
Spring Boot让Redis集成变得异常简单。@EnableCaching注解开启缓存支持,@Cacheable注解标记需要缓存的方法。这种声明式的方式确实优雅,但也要注意它的默认行为可能不符合所有场景。
序列化方式的选择很关键。JDK序列化虽然方便,但性能较差且可读性不好。Jackson或FastJSON序列化能提供更好的性能和可调试性。我一般推荐使用StringRedisSerializer配合JSON转换,这样既能在Redis命令行里直接查看数据,又能保证序列化效率。
缓存配置应该考虑环境差异。开发环境可能不需要复杂的缓存策略,但生产环境必须配置连接池和超时设置。使用@Profile注解区分不同环境的配置是个好习惯。
异常处理经常被忽略。Redis服务不可用时,系统应该优雅降级而不是完全崩溃。可以通过配置fallback方法,在缓存失效时直接查询数据库。这种设计能让系统在部分组件故障时继续保持可用。
测试同样重要。不仅要测试缓存命中的场景,还要测试缓存失效、异常等各种边界情况。Mock一个Redis服务器来模拟各种异常条件,能帮助发现很多潜在问题。
3.1 缓存性能监控与调优技巧
监控缓存性能就像给系统做体检。info命令能提供丰富的基础指标,命中率、内存使用情况、连接数这些数据都需要定期关注。我习惯在grafana上搭建监控看板,把关键指标可视化,异常波动一眼就能发现。
慢查询日志是个宝藏。配置slowlog-log-slower-than参数记录执行时间过长的命令,经常能发现意料之外的问题。曾经有个项目突然变慢,查慢日志发现是某个同事写的Lua脚本执行时间超过100毫秒,优化后性能立刻提升。
内存优化需要细致入微。当used_memory接近maxmemory时,Redis会根据配置的淘汰策略开始清理数据。volatile-lru通常是个安全的选择,只淘汰设置过期时间的key。如果业务允许数据丢失,allkeys-lru可能更合适。
碎片化问题容易被忽略。mem_fragmentation_ratio超过1.5就该警惕了,这时候重启实例或者升级到4.0以上版本使用主动碎片整理功能会很有帮助。
3.2 分布式环境下的缓存策略设计
分布式环境下,缓存策略要考虑的维度更多。一致性哈希是个聪明的设计,节点增减时只有少量数据需要迁移,不会导致整个缓存失效。我见过用传统哈希取模的系统,增加一个节点就让缓存命中率暴跌,那场面确实让人头疼。
多级缓存架构在实践中很有效。本地缓存+分布式缓存的组合能极大降低Redis的压力。Guava Cache或者Caffeine作为一级缓存,存储热点中的热点数据,Redis作为二级缓存提供分布式共享。这种设计在秒杀场景下特别有用。
缓存预热不能忽视。新系统上线或者大促前,提前加载热点数据到缓存中,避免冷启动时数据库被冲垮。可以基于历史访问模式预测热点,也可以通过日志分析找出高频访问的数据。
读写分离策略值得考虑。主从架构下,读操作可以分散到多个从节点,写操作集中在主节点。但要小心主从延迟带来的数据不一致问题,对一致性要求高的查询还是应该走主节点。
3.3 实际业务场景中的缓存策略选择案例
电商商品详情页的缓存设计很有意思。商品基础信息变化不频繁,可以设置较长的TTL,比如30分钟。库存信息变化频繁,TTL要短一些,可能只需要10秒。价格信息更敏感,可能需要实时更新,这时候可以考虑主动更新策略。
用户会话管理是另一个典型场景。Session数据通常设置统一的过期时间,比如30分钟。但要注意续期机制,用户每次操作后都应该刷新过期时间,否则会出现用户操作到一半突然被登出的尴尬情况。
新闻类应用的缓存策略需要平衡实时性和性能。头条新闻可能需要秒级更新,但历史新闻缓存几天都没问题。可以按新闻的发布时间设置阶梯式TTL,越新的内容TTL越短。
搜索建议的缓存很特别。用户输入前几个字母时出现的提示词,可以缓存较长时间,因为热门搜索词不会频繁变化。但要注意缓存粒度,应该按搜索前缀缓存,而不是整个结果集。
3.4 常见问题排查与解决方案
内存使用异常增长是个常见问题。除了业务数据自然增长,还要检查是否有大量无用的key堆积。scan命令配合模式匹配能帮你找出这些“僵尸key”。我曾经发现一个系统里有几百万个临时key忘记清理,清理后内存使用直接降了一半。
连接数异常上涨往往意味着连接泄漏。监控netstat输出,观察ESTABLISHED状态的连接数变化。客户端代码里没有正确关闭连接是最常见的原因,使用连接池能很大程度上避免这个问题。
CPU使用率突然飙升需要快速定位。可能是某个大key被频繁访问,也可能是触发了持久化操作。monitor命令能实时查看所有操作,虽然对性能有影响,但在紧急情况下很有用。
网络问题导致的超时很难排查。跨机房访问、防火墙配置、带宽限制都可能成为瓶颈。我建议在应用服务器上定期用redis-cli测试连接延迟,建立基线数据,异常时能快速对比。
数据不一致的排查需要耐心。先确认是缓存问题还是数据库问题,再检查更新逻辑是否正确。加一些详细的日志记录缓存读写过程,虽然会增加系统开销,但在排查复杂问题时非常值得。